Kikibot
From 40 hours to 4 hours
- Created a set of Jupyter notebooks to automate the creation and uploading of assets and platform images, enhancing workflow efficiency tenfold.
- Scraped competition pages using Selenium + Puppeteer for easy acquisition of match and player data
- Widely used by my company’s live operations team to maximize efficiency and reduce the margin of human error during busy periods.
- Utilized Python, Selenium, Puppeteer, and Google Sheets API to build the automation aspect of the bots, running fully functional on Google Colab to increase usability.
Disclaimer: All information divulged here has been out of date for quite some time, therefore safe to share.
Background
It all started when my friend at work was complaining about having to make assets for a rugby competition.
You see, in a typical rugby competition season running roughly for 12 weeks, there are on average about 120 games. The way these games would be presented on platform would be as individual tiles.

So how do all these tiles get made? In the backend, someone would have to have made two sets of “assets” to form one individual tile.
Firstly was the metadeta, or what we call, ‘shells’. We made them in Google Sheets, then imported them into our content management system. they were typically around 4 rows, a row for the main asset, and subsequent ‘opens’ or other assets linked to the main asset like mini matches, highlights, and rapid recaps. Each row had 20 or more columns to them that had information spanning anywhere from the type of competition it was, e.g ‘Shute Shield’ to the year or the round of that particular game. And mind you, all that for one game. If you multiply these 4 rows and 20+ columns by 120, you could see how much work that would be.
Secondly was the images. Yes we’d have the metadata done but what about the ‘frontend’ for the tiles? At this point-
TLDR: It’s very boring to make tiles for platform.
So to save my friend from hours of tedious work, I spent three days brainstorming and experimenting to find a solution. Previously, I had heard of Selenium being used as test automation software to perform integration tests on websites like Amazon.
Selenium is an open source framework that can be used for automating web browsers. It mimics human actions on websites by controlling the browser; clicking buttons, filling forms, navigating pages - using scripts written in languages like Python.
Prototype of image generation
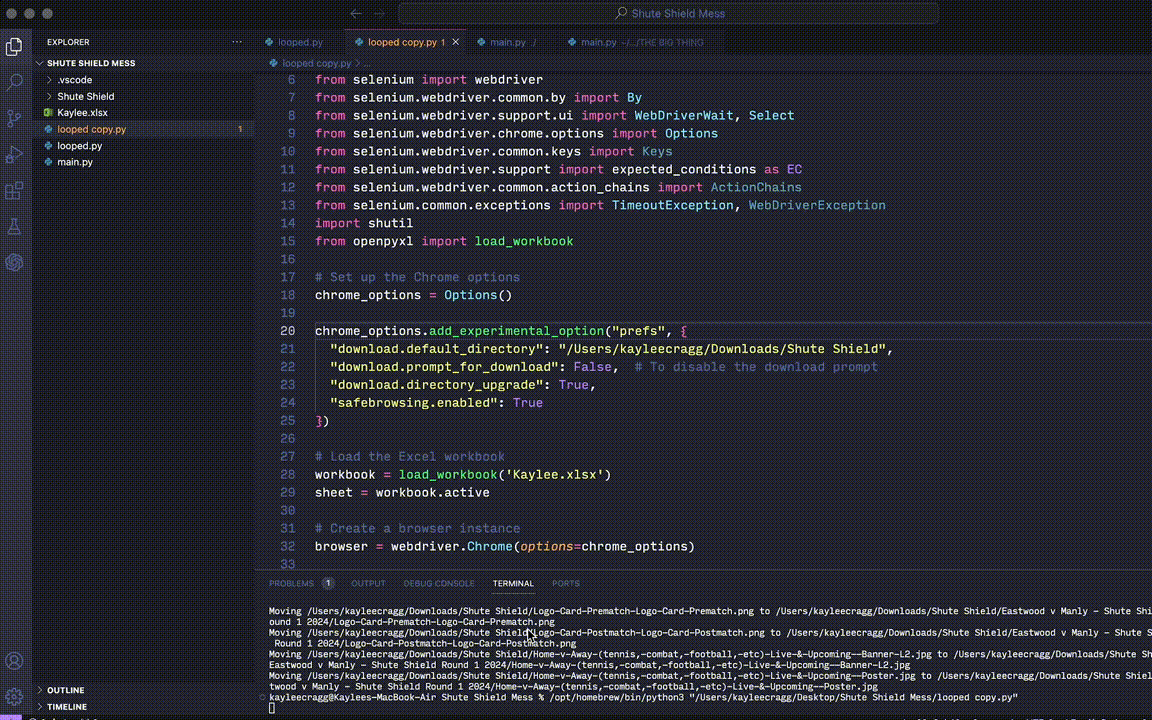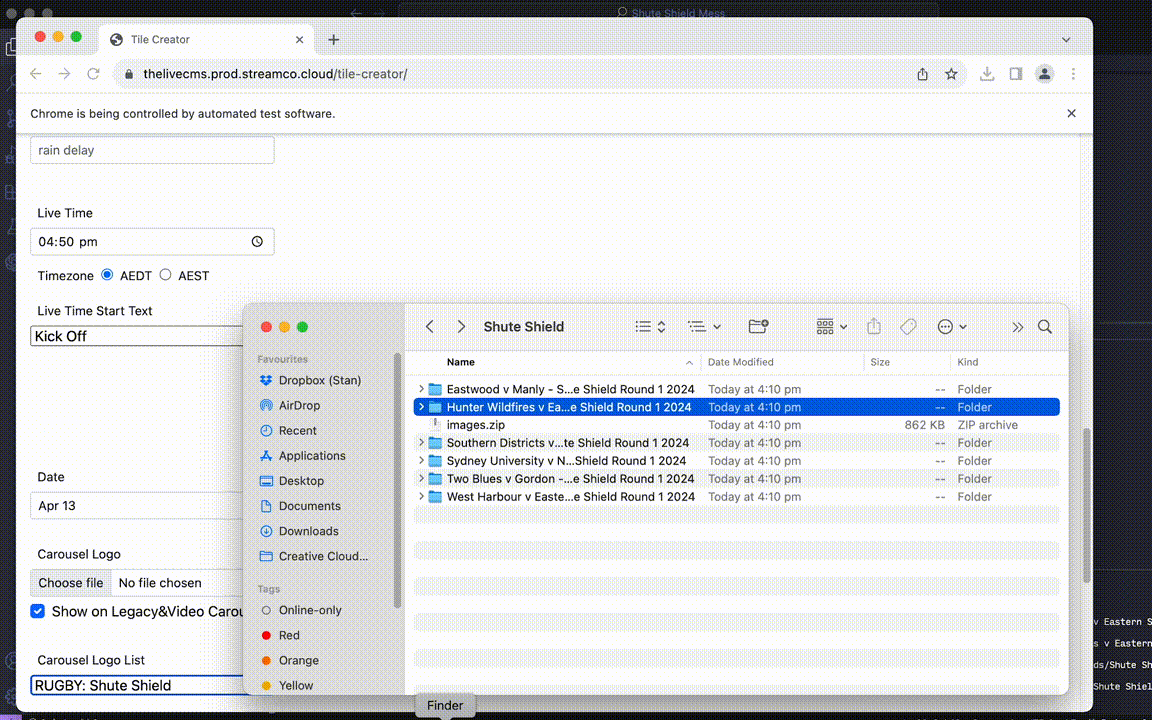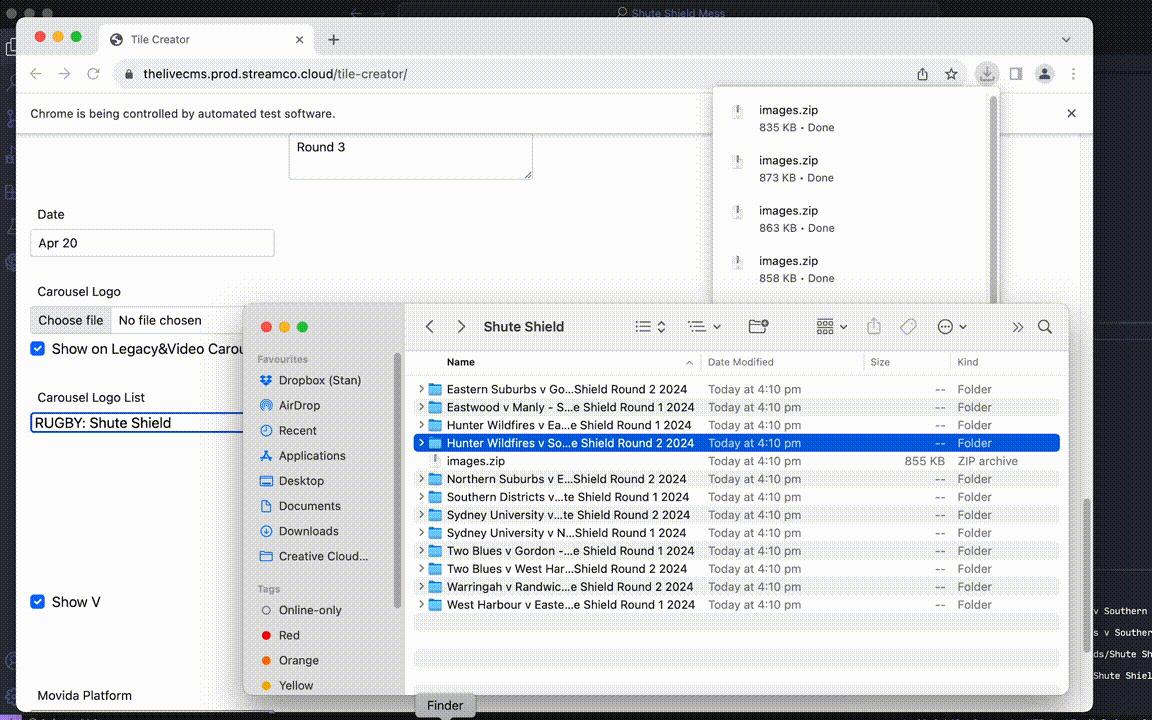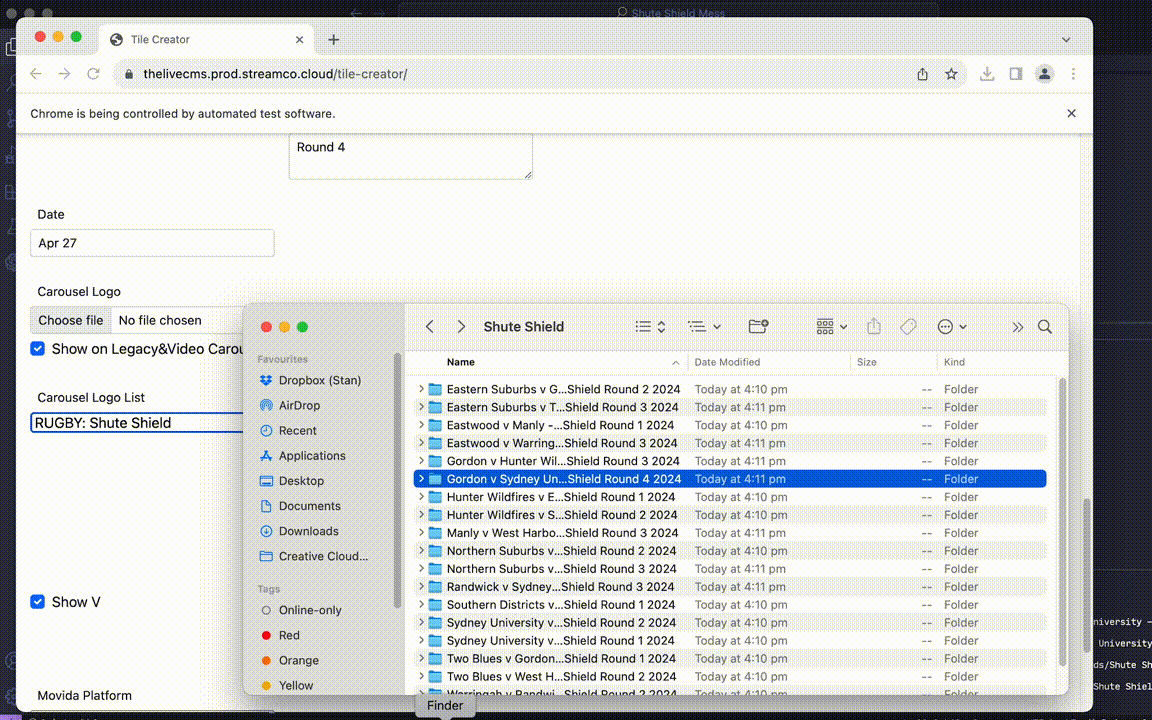
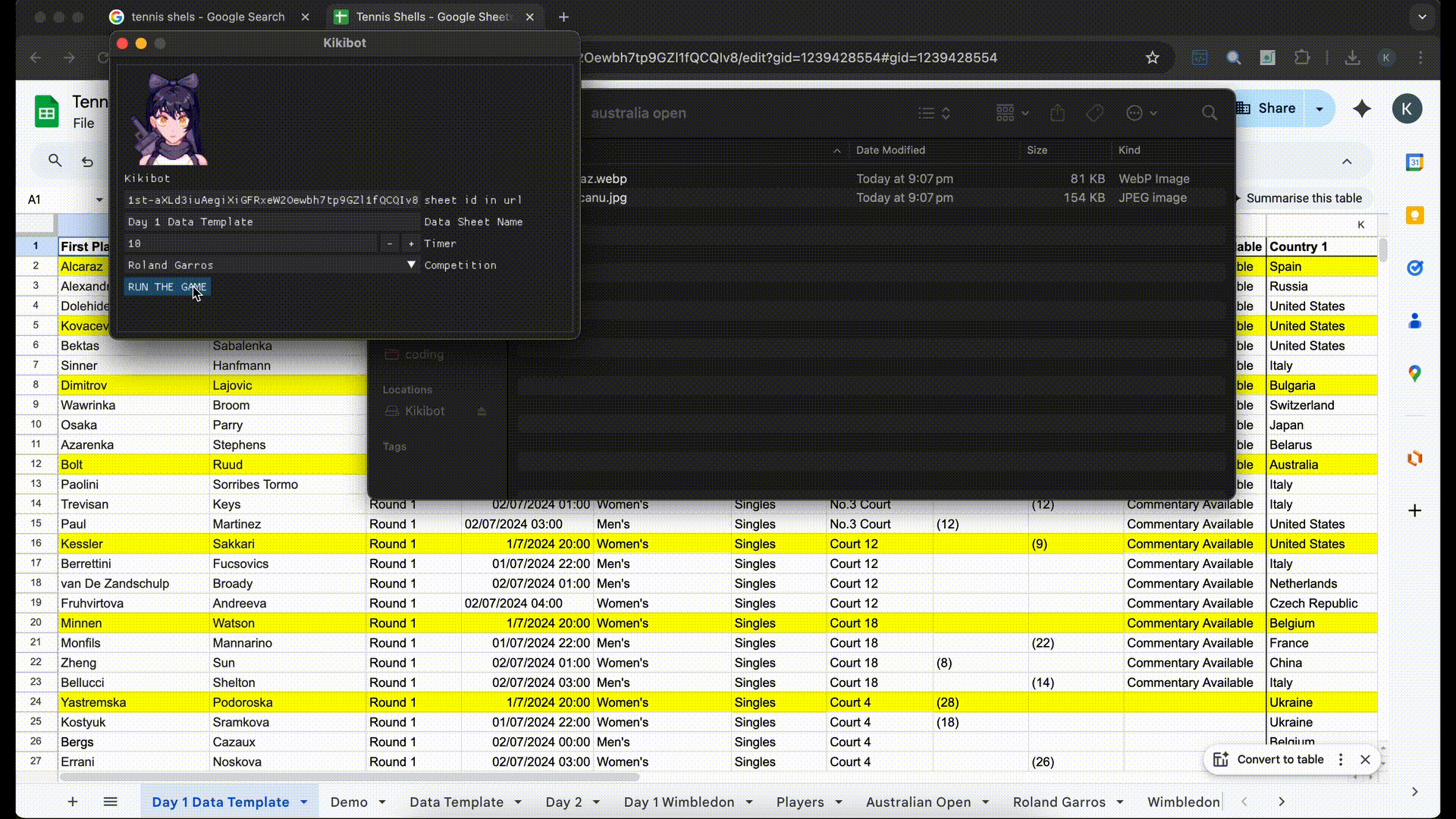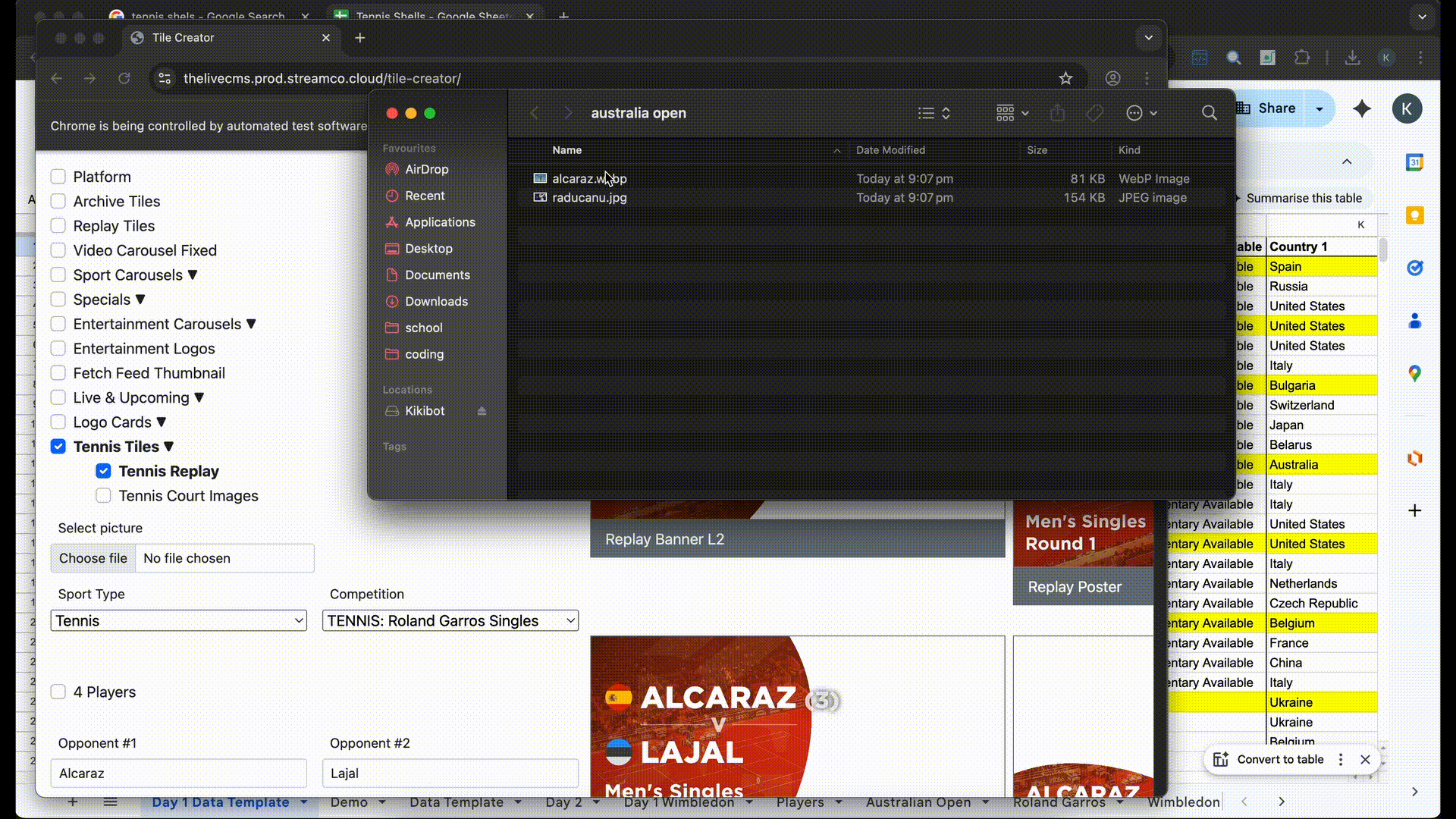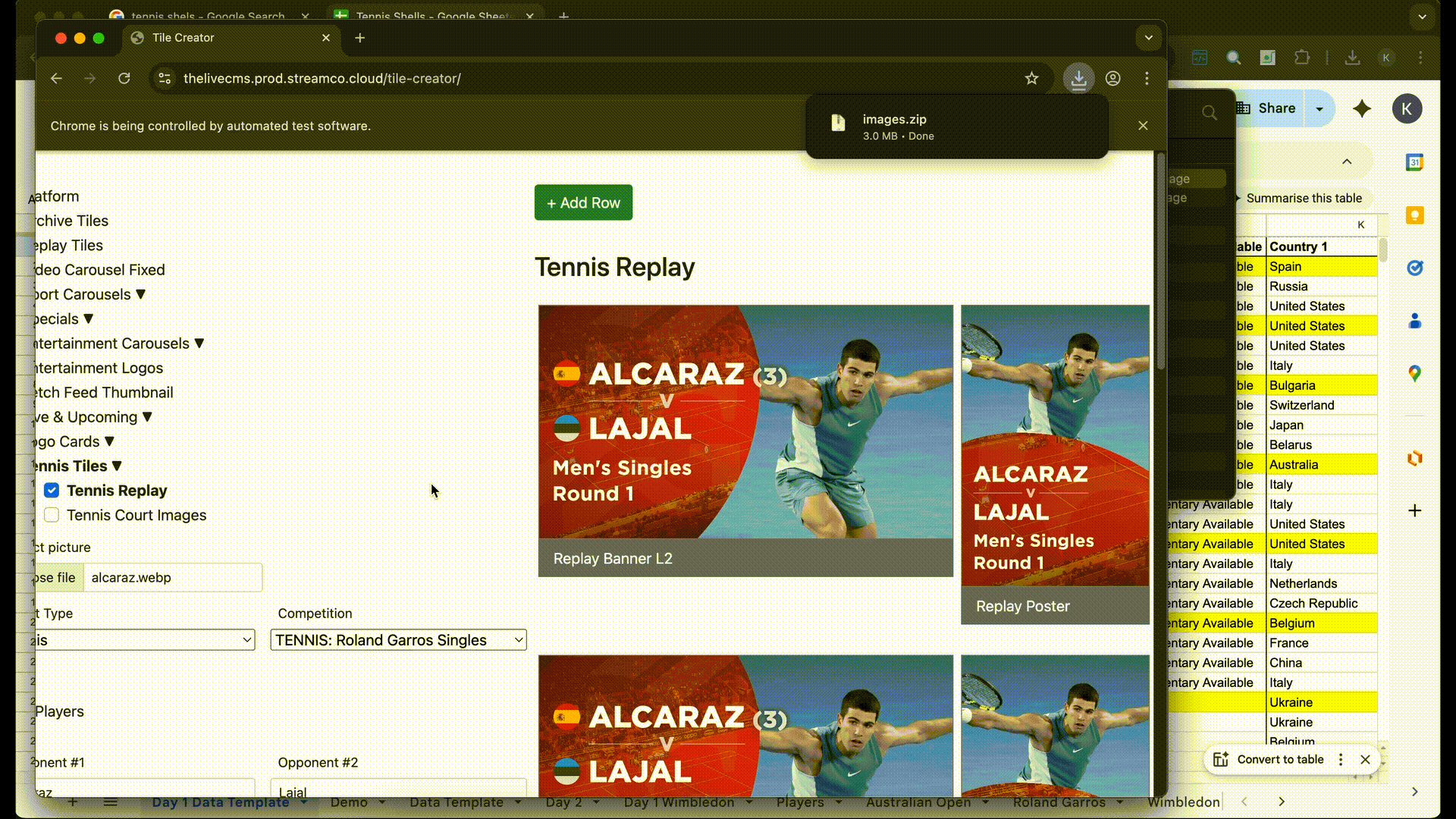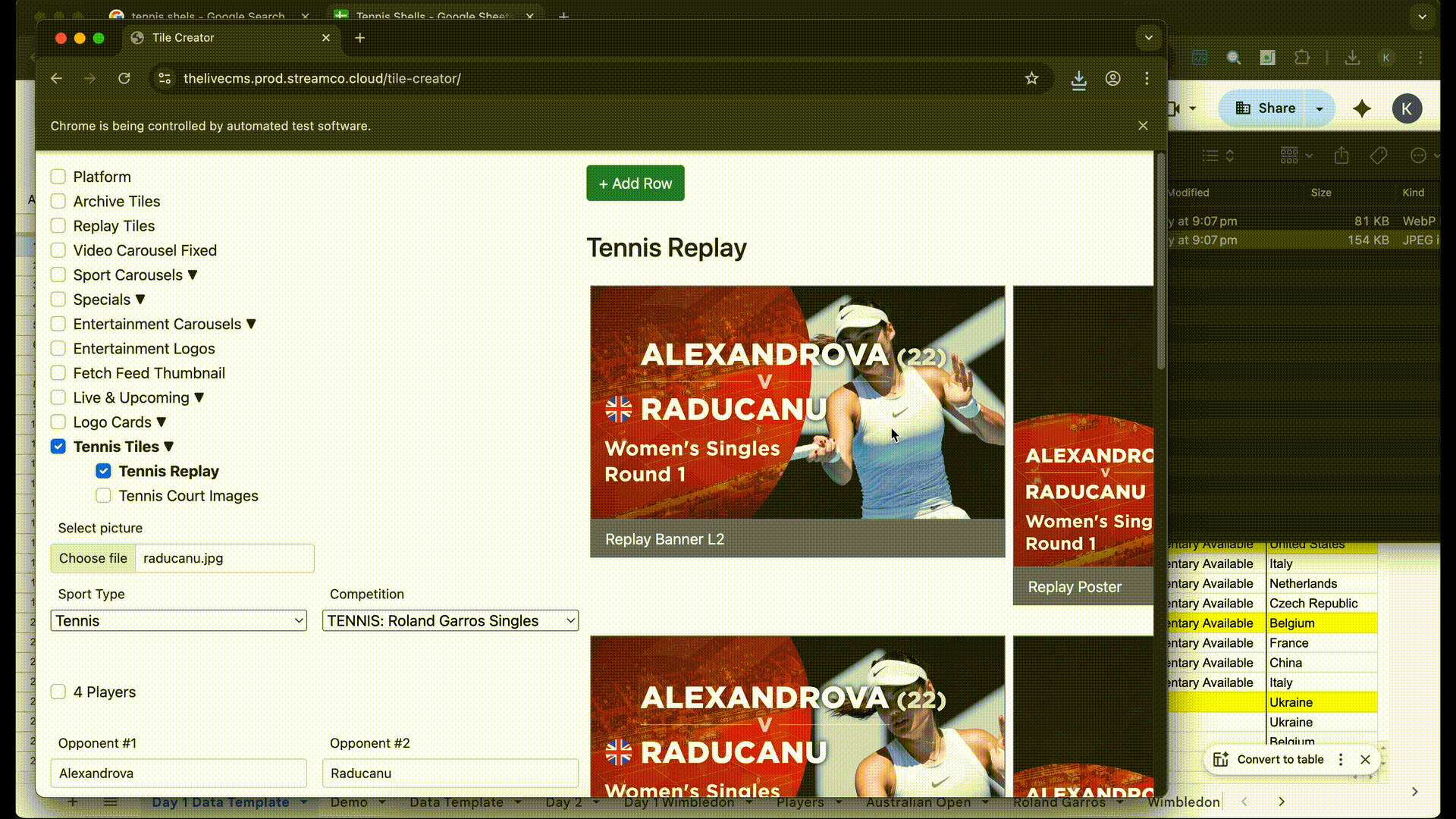
With that in mind, I began experimenting with ways to make Selenium interact with our company’s tile creator, web application used to generate pre and post match images for our platform.
- I initially had Kikibot running locally with Python in conjunction with a local .xlsx file that had all the match information.
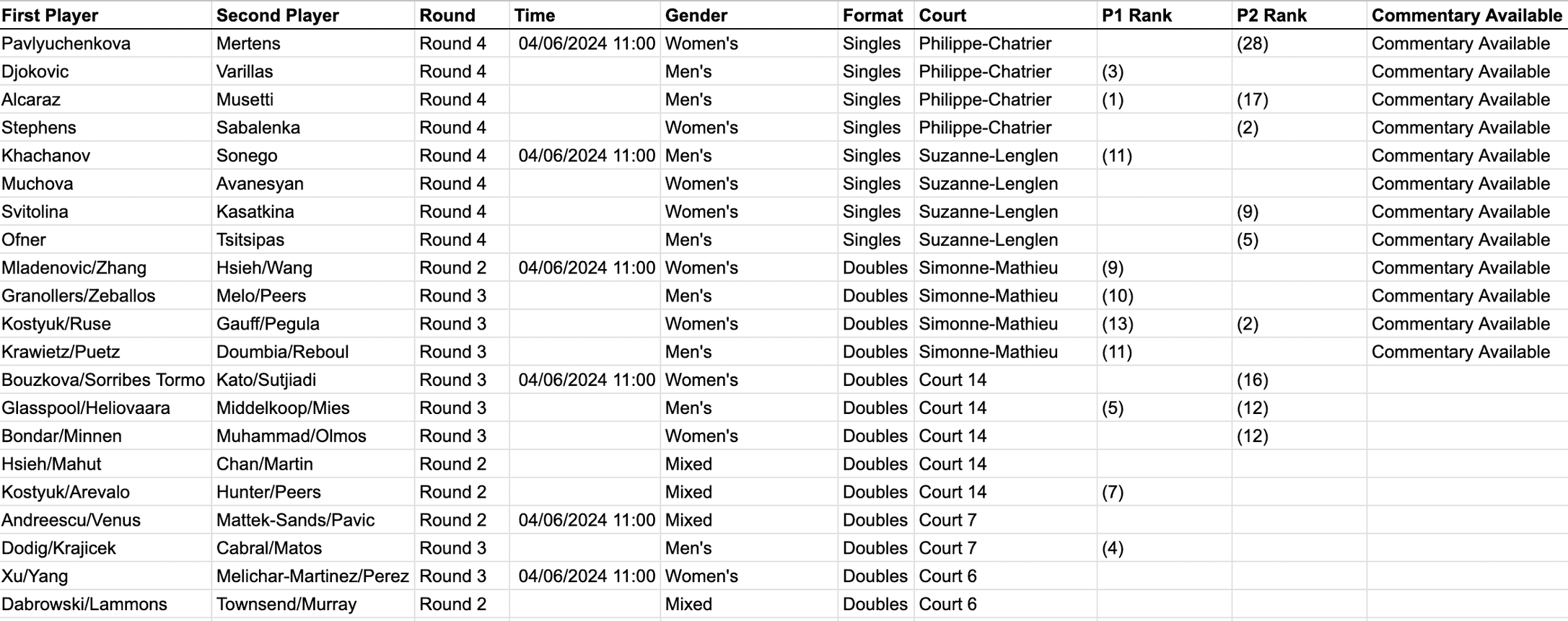
- When ran, Selenium would manually open up the tile creator website and enter all the details in their respective input fields based on the specifications in the xlsx file. (e.g; country, player names, round, competition, year, sport)
- Once done, it would click on the download images button and save the image folder into a parent folder, and rename each match’s images accordingly.
I messaged my friend, and then my team lead, excited to show them my new creation.
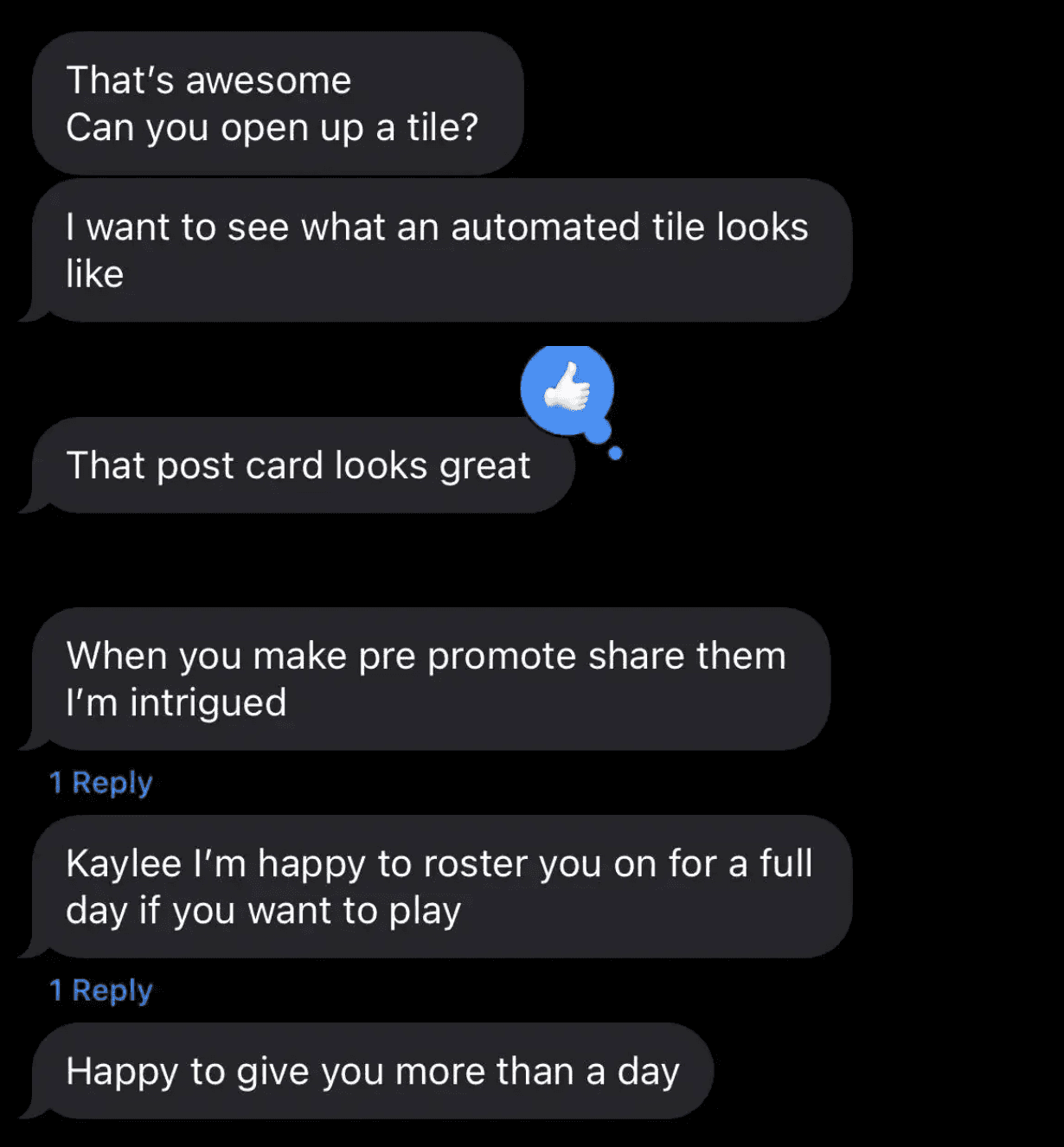
My team lead gave me a few more days to tinker with it and then she invited me to a meeting with both her and my boss to showcase the abilities of this new tool.
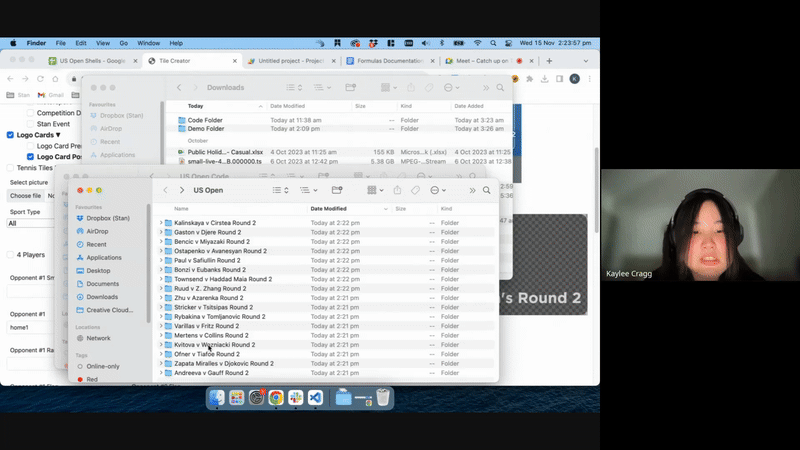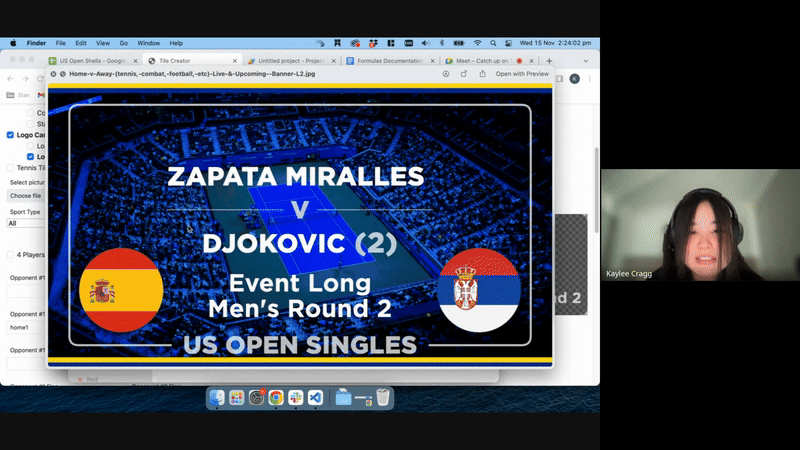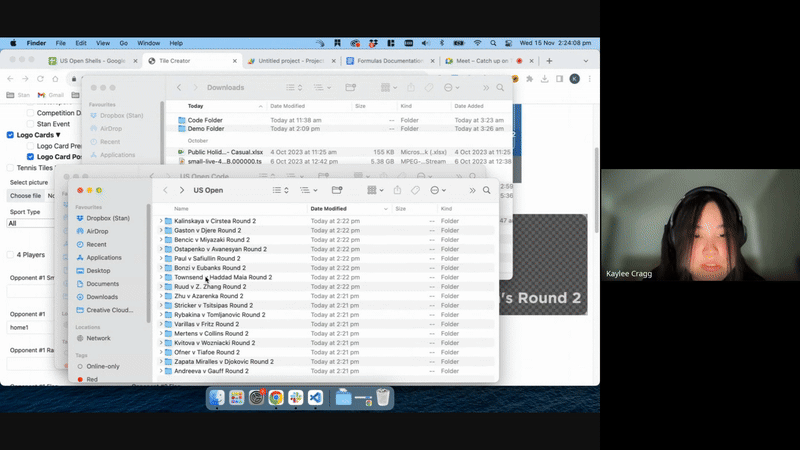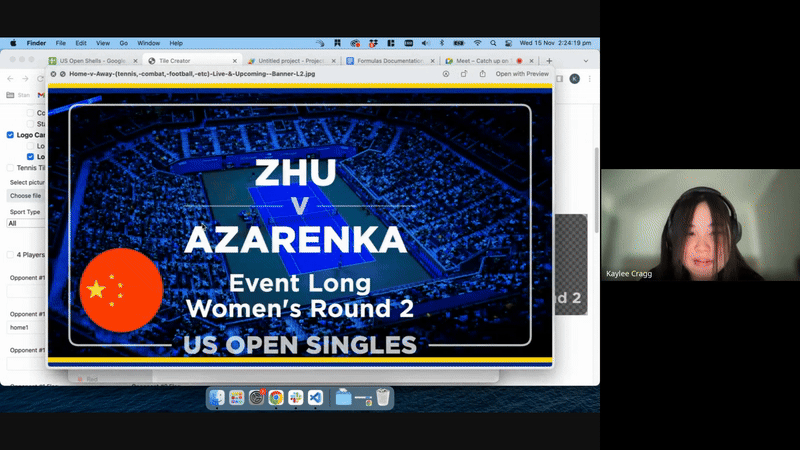
Expanding upon the prototype
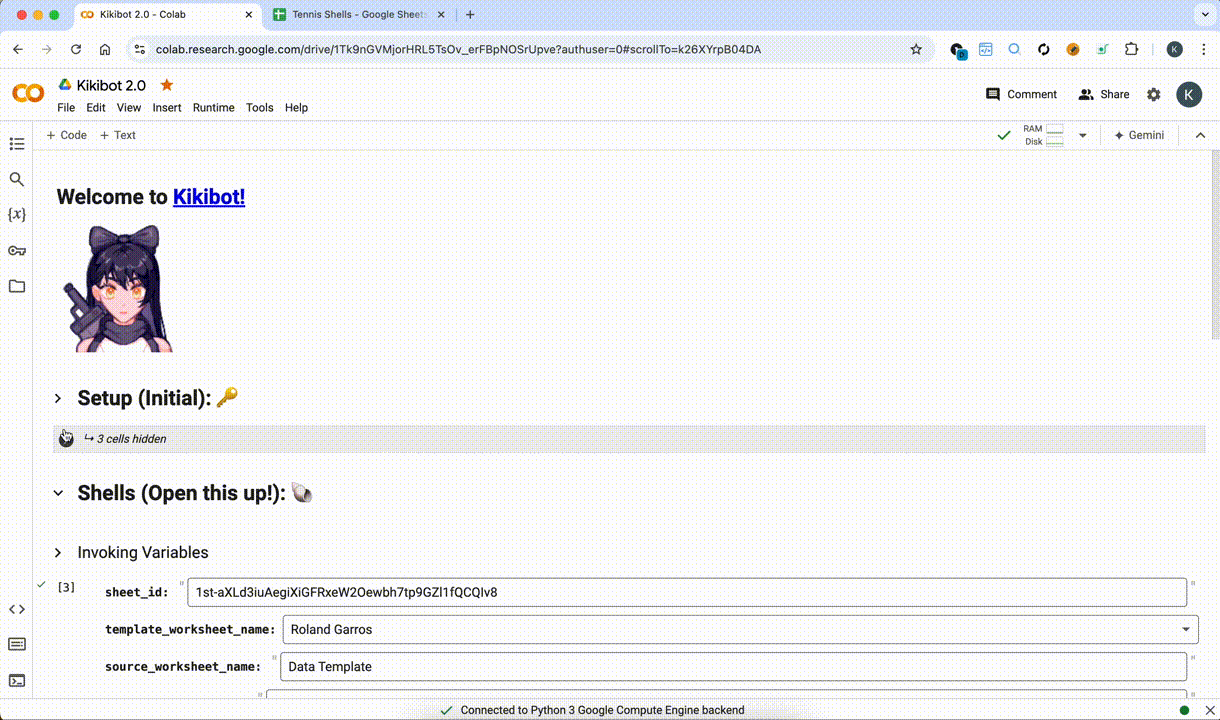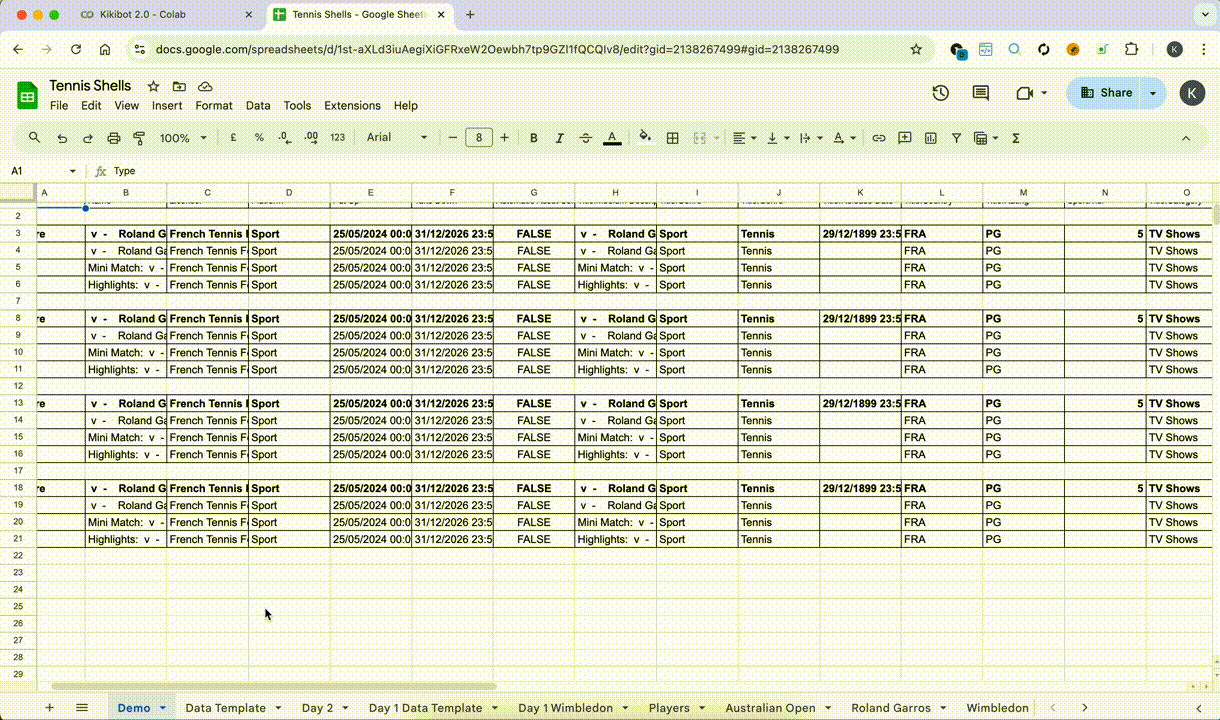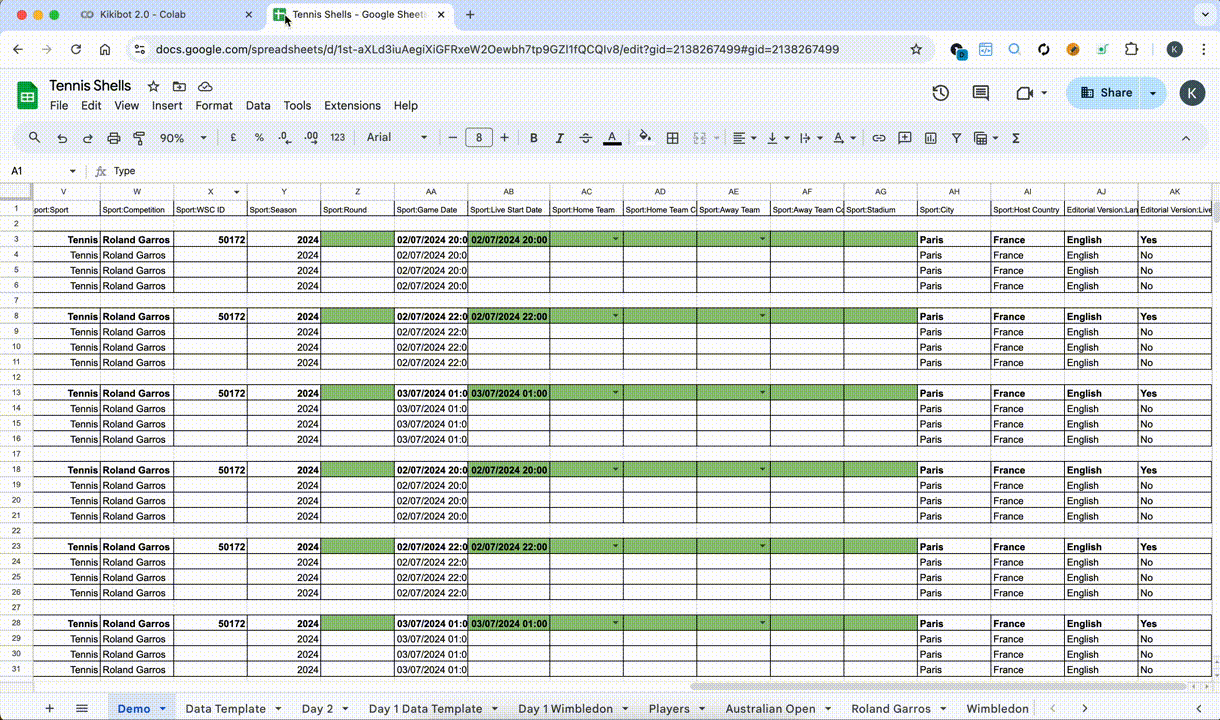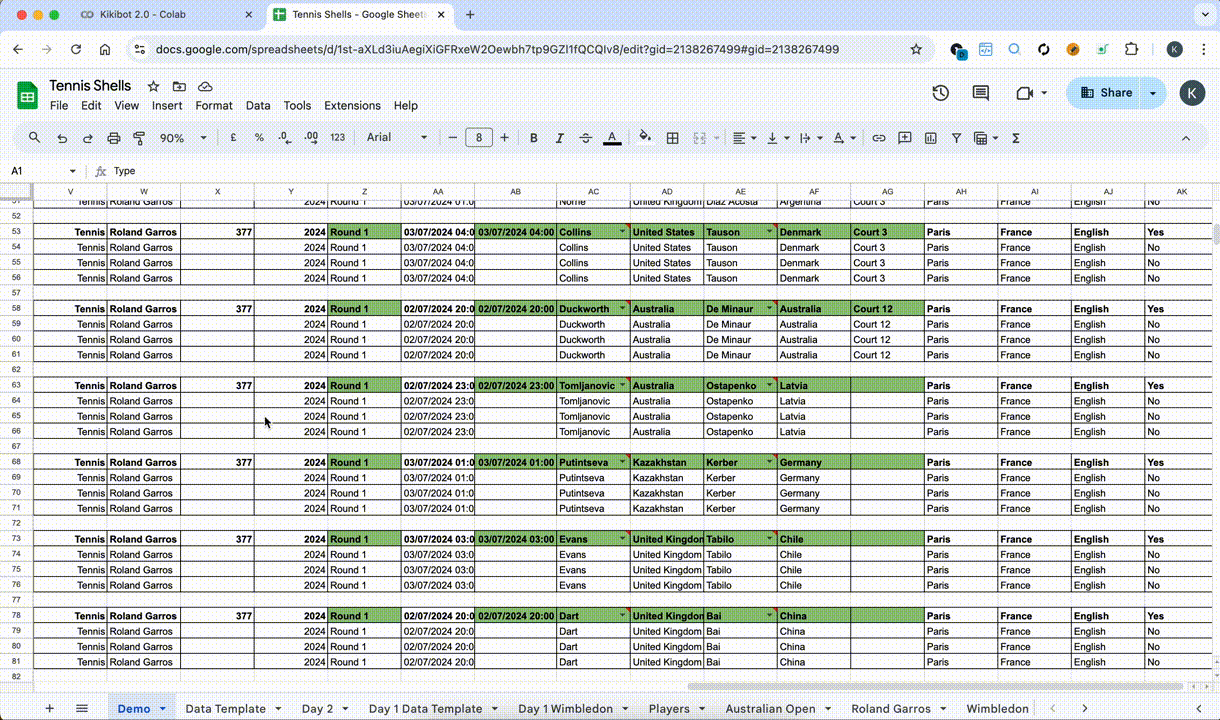
- Moved from local Excel sheet to Google Sheets with Google Sheets API, easier.
- Expanded Kikibot’s capabilities to cover Google Sheets API, able to batch input information based on the data sheet and was thus able to completely automate the asset making aspect of the job
- Kikibot was able to scrape competition page (Aus open) using Selenium + Puppeteer for easy acquisition of match and player data
- Puppeteer (another web automation software, which was built in Node) was necessary because the competition page was made in React and needed Javascript to interact with, which was out of Selenium’s abilities
Postbot
Okay so now we’ve made the shells and the pre-images for the games. What about post images?
Pre-images were straightforward: automated in Google Colab using Selenium’s headless mode (different to what you saw before, Selenium in it’s headful mode manually opens up the web page you want to automate - in headless mode will no longer be able to ‘force’ the web browser since Colab itself runs in a browser, Selenium couldn’t launch a visible window). Combined with the Google Sheets API, the process was fully automated, no manual intervention needed.
Post-images, however, introduced a new challenge: dynamically importing and adjusting a player’s photo. This step couldn’t be automated within Colab since there was no window to resize it in. Manual resizing and tweaking in the tile creator meant the process had to shift from cloud-based to local execution.
So, I made an DearPyGui GUI application that was bundled with the local Kikibot script specifically built for creating post images and packaged it into a .dmg file so that it could be downloaded onto Macbooks. (work laptop OS)
Impact
So how exactly did this boost shareholder value?
During the time I created this automation, my team was very short staffed. Everybody was working long hours for days on end. I myself at one point worked 19 days in a row, some of them being 13 hour days.
I was also working else where, so I didn’t have much time at all to devote to working and helping out during this very busy tournament period. I could at most only work from 6pm onwards until midnight, (6 hours) preferably less. Which is a great segue to the next issue at hand;
According to previous rosters (January, May, July, September), there were on average 5 people rostered on to complete the whole image/asset creation process (before the automation).
Name - Shells: 9am - 5pm
Name - Shells: 9am - 5pm
Name - Pre-promote images: 6am - 2pm
Name - Pre-promote images: 6am - 2pm
Name - Post images: 9am - 5pm
In total: 40 hours spent in one day
How was I suppose to fit forty hours of work into six? I didn’t. I did it in four.
And in total, saved the company about $25,000 AUD. (per grand slam.)
I included all of these findings in a report that my team leads requested from me after the tournament was over.
If you wanna see some truly nerdy stuff, here are more technical details of my report
Overview
- The shell and images automation process started as a set of Jupyter notebooks hosted on Google Colab that automate the creation of shells and images through the image creator tool by reading data in a google sheets with Google Sheets API, which was attained by scraping the competition’s website.
- Has been used to maximise efficiency and lower the margin of human made error during busy periods (grandslams).
Currently the package comprises of:
Shell bot
- Currently configured for Australian Open, Brisbane International, Adelaide International, United Cup.
- For Australian Open, it scrapes AO’s website to automatically download match information, reducing the need to painstakingly manually input match information which can be prone to mistakes and spelling errors.
- For the smaller competitions (i.e Brisbane International, Adelaide International, United Cup), shell generation relies on manual data entry into the ‘data’ worksheet of the Tennis Shells google sheet.
Pre Images bot
- Currently configured for Australian Open, Brisbane International, Adelaide International, United Cup pre images.
Post Images bot
- Almost the same function as Pre-images bot but instead configured for making Tennis Replay images instead.
- At this point the images would need to be prepared and manually uploaded and adjusted in the tile creator but the rest of the information is automated.
(there’s also a Future works in progress / recommendations section but most of these issues had been fixed by the time May rolled around so I’m going to omit them. what happens in May? read on)
Team lead: I want you explain in writing how you automated the tile creator and shell process.
Setup: Downloading/installing necessary packages/libraries
Downloading JSON key from dropbox
- JSON key is required for using google sheets api
- Installing/upgrading gspread libraries + Node.js
- Gspread is required for using google sheets api
- Node.js is required for using Puppeteer
Installing Puppeteer
- Puppeteer is required to scrape Australian open’s website as it is rendered with React First section: Scraping Australian Open webpage to HTML file
First section: Scraping Australian Open webpage to HTML file
Enter the URL to Scrape
- Each day needs a separate input
- The link will look something like this https://ausopen.com/schedule#!40015
Writing scraping instructions in index.js file
- Writing instructions into a Node.js file that will open up a browser, go to the link you input, and scrape the whole webpage into a html file named ‘Scraped.html’
Running index.js file
- Running the Node.js file so that the Scraped.html file will be created and stored for future use Second section: Taking data scraped from Aus open website to Google Sheets/ AKA Shells
Second section: Taking data scraped from Aus open website to Google Sheets/ AKA Shells
Invoking Variables
- Minimal input needed (do this before you run the whole section, but should only need to do once per competition)
- Just has things like credential file location (static), sheet_id (once per comp), template_sheet_id (once per comp), template_worksheet_name (once per comp), sheet_range (static, unless programming adds additional columns to the sheet.. 😰 )
Parsing data from HTML file to Google Sheets
- Extracting raw data from the scraped html file like Round, Time, First Player, Second Player, Gender, Court name, ranks of the players, and match numbers and writing them into a data sheet in google sheets (which google sheets can be specified in the invoking section), interating the data over each match until there are none left.
Parsing the existing times
- Takes the existing times from certain matches and assigns them to the respective matches in the google sheets.
- Why is this separate? Because this feature was implemented later on in the development stage and it got too complicated to combine into previous script
Calculating the rest of the times
- As there is now a bunch of matches without times right now, this script fills in the matches without times assigned to them by calculating the times between them. For example, if the previous match was a Men’s Singles match, then it would add 3 hours to the previous start time, for anything else it would add 2 hours to the previous start time, skipping over matches with already assigned times. If there time that was assigned for a new court then it would interate over it.
Setting up initial Day from template
- This script copies over the initial two match structures from the template worksheet into a new worksheet named; ‘Day (Day number)‘.
- Why is this separated from the rest? Because the first match’s structure can’t be duplicated without causing the error which stems from vlookup.
Copying over from match template based on amount of matches
- With the first match’s structure out of the way, this section of the script duplicates the second match’s structure as many times as there are matches that exist for the day.
Copying over match data from data sheet
- Now that the structure for all the existing matches are in, it’s time to write in the match data column by column. (mostly from the data sheet)
- Why is this done secondly and not concurrently to the previous step? Wouldn’t it be more efficient/faster?
- Because the data validation/formatting needs to pre-exist before the match data is inputted, it is safer to have all of the match structure already in the sheet before inputting any match data
Tennis Pre-Images:
Installing Selenium
- Selenium is required to interact with the tile creator tool as it is rendered with Javascript
Downloading Flags folder from Dropbox
- A Flags folder that contains all every flag from every country is downloaded from dropbox so that it can be used locally in the colab environment
- Also has some competition logos because tile creator is just severely lacking.
Doing the prepromotes
- This section of code automates the creation and downloading of Live & Upcoming tiles and Post match logo cards for the Australian Open using a headless Chrome browser and data from the ‘Tilebot’ worksheet that was extracted from the Shell creation processs in Google Sheets. It involves the following steps:
- Setting Up Environment and Browser: Imports necessary libraries, sets up a folder called ‘Prepromotes’, where all the pre image files and folders will be downloaded into, and configures headless Chrome browser options for automation. (Necessary for colab environment where there is no GUI)
- Google Sheets API Integration: Initializes Google Sheets API to fetch data from the ‘Tilebot’ worksheet in a specified Google Sheet, which contains details like player names, countries, match dates, and rankings.
- Web Automation with Selenium: The script uses Selenium WebDriver to interact with the tile creator tool. It navigates through the tool’s interface, selecting options based on the data fetched from the Google Sheet, such as the type of match, player details, and country flags.
- Input Handling and Data Entry: The script inputs data into the web tool, including player names, rankings, and match details. It also handles file uploads for country flags and manages exceptions and timeouts.
- Downloading and Organizing Files: After inputting all the data, the script triggers the download of zip files containing the tiles. It waits for downloads to complete, extracts the zip files, and organizes the extracted files into specific named folders based on the names of the players and the match type (singles or doubles).
- Finalization and Clean-Up: The script compresses the organized folders into a zip file and triggers its download. Finally, it cleans up any temporary zipped files and closes the browser session.
Outcome: Winning an award!
So, I won an award! It’s like an internal company peer bonus where people can vote for the winners, and those who gets the highest amount of votes wins.



Wait, there’s more?
Aftermath
Yes there’s more!
The events that transpired beforehand all took place during the Australian Open (January), one of four tennis grandslams my company covers. The next one will take place in May. However, prior to this I also had to go overseas for 3 months, meaning I wouldn’t be available to run my bot. Well, just hand it off to someone?
- First of all, it wasn’t polished. There were stil plenty of bugs that happened that I barely was able to fix in the heat of things just enough to get everything running.
- Second of all, nobody actually knew how to use it; there were many steps to the process and it was more than could be put into a simple handover message.
- Third of all, Postbot wasn’t actually made at this time. So the whole time in January the post images were just made with a hastily put together locally ran raw Python file and me madly shoving images in before the timer
time.sleep(30)in the Selenium loop closed on me.
So I was invited into another meeting with both my boss and lead to discuss what comes next.
We settled on a solution which involved me optimising the Google Colab environment to make it less buggy and more readable for people not so familiar with technology.
I then ran a crash course that spanned 2 weeks teaching over 10 co-workers and my 2 team leads on how to use my tool and troubleshoot any issues that may arise.
This section is still WIP.
What happened after? Well that tournament went fine, but halfway through the next tournament a better version was brought in by our company’s tech team that made my tool redundent.